Vous êtes maintenant convaincu(e) de l’intérêt de lancer un projet data pour répondre à vos problématiques d’entreprise. Mais comment se déroulera concrètement le projet data ? Quelles technologies et architectures choisir, et quels impacts sur l’organisation de votre entreprise ?
Projet data, mode d’emploi !
Quelles technologies mettre en place ?
Un projet data nécessite la mise en place des systèmes de traitement de la donnée tout au long de la chaîne de valorisation de celle-ci. A chaque étape du projet, des choix sont à faire sur les technologies et langages utilisés. Ils dépendront de votre organisation, des données à traiter, et des problématiques à adresser.

Système de stockage
Le choix du système de stockage à mettre en place dépendra de la nature et de la volumétrie de la donnée, mais surtout du besoin métier à solutionner. Par exemple, le choix d’une base de données relationnelle (mySQL, SQL Server) ou non-relationnelle (noSQL).
Pour les volumétries importantes (Big Data), on met en place des systèmes de stockage de données plus complexes, comme des data lakes. On peut citer des solutions comme Hadoop, Azure Data Lake, S3, GCS…
Technologie du système de stockage et architecture sont interdépendantes, le choix du système de stockage doit donc se faire en même temps que celui de l’architecture.
ETL / ELT
Extract, Transform, Load : on souhaite extraire la donnée, la transformer, puis la charger. N’importe quel langage informatique peut être utilisé pour créer les algorithmes correspondants. Souvent, on utilise Python, R, C#, Java, Scala…
Pour le traitement des données stockées sur des environnements distribués (Big Data), des spécifiques existent et permettent d’effectuer des traitement multi-machines.
Sinon, des logiciels “Boite à outils” permettent de réaliser ces étapes ETL / ELT à l’aide de certains composants, de les paramétrer selon le type de données et de leur faire effectuer des traitements sur celle-ci : Airbyte, SAP BO DS, SSIS, Talend…
Data Lineage / Gouvernance logicielle

Data Lineage
Une fois le processus d’alimentation mis en place, il faut pouvoir suivre la provenance des données, consulter ses informations et les traitements qu’elle a subi. C’est à cela que sert le Data Lineage : pouvoir observer toutes les évolutions et le chemin suivi par la donnée. Cela permet par la suite de repérer plus facilement les interactions dans le cas de modifications ou d’erreurs, et facilite la maintenabilité.
Gouvernance logicielle
Les données traitées peuvent venir de différentes sources, et peuvent concerner plusieurs métiers. Même si elles sont stockées au même endroit, les paramètres d’accessibilité ne peuvent pas être les mêmes pour toutes les données stockées.
Une démarche de gouvernance de la donnée est donc indispensable : il faut déterminer qui peut accéder à quelle donnée, et l’organiser ensuite selon le besoin afin de mettre la bonne donnée à la disposition de la bonne personne
A ce titre il existe des outils permettant de cataloguer les données de l’entreprise, par exemple Collibra, Zeenea, Amundsen…
Exploitation & Exploration
Une fois les données extraites et stockées, c’est le moment de les exploiter selon les cas d’usages prévus au lancement du projet.
Avoir ce large volume de données permet également de chercher et vérifier de nouvelles thèses, corrélations, pour trouver de nouvelles façons de valoriser la donnée qu’on a à dispo. C’est la partie « chercheur d’or » du projet data : la donnée brute est explorée afin d’imaginer des thèses, des corrélations. Si besoin, des clusters de données sont créés selon la nature de la donnée pour enfin générer le modèle qui répondra au besoin métier.
Plusieurs types d’acteurs interviennent lors de cette étape afin de valoriser la donnée. Le Data Scientist par exemple a plusieurs outils à sa disposition pour explorer la donnée : Jupyter Notebook (exploration), Knime (analyse et modélisation), Python (traitement spécifique, utilisant par exemple des bibliothèques spécifiques à la data science comme matplotlib ou scikit-learn).
Si besoin, c’est également à ce moment que l’on met en place la gestion des couches sémantiques. Les utilisateurs finaux des données en parlent avec un vocabulaire « métier » non-technique, ce qui demande donc une conversion pour la leur rendre utilisable.
Des technologies comme SSAS, Cognos, permettent dans la solution de convertir l’appellation technique de la donnée (par exemple, la colonne B12) en libellé métier (par exemple « salaire brut »). Cette transformation devient une source de donnée en elle-même : c’est ce qu’on appelle la couche sémantique

Restitution & Mise à disposition
De nombreux outils existent pour créer un tableau de bord, du simple Excel à des outils spécifiques de restitution de données. Ces logiciels de visualisation de données (comme PowerBI, Qlik, Tableau…) sont souvent utilisables directement par les métiers, après une formation initiale.
La restitution peut également prendre la forme d’une nouvelle donnée ou d’un nouveau jeu de données ; par exemple, dans le cas d’un besoin demandant une prédiction d’une information.
Souvent, la restitution permet de répondre à une ou des questions apporteuses de valeur pour une entreprise (Business Intelligence).
Quelle architecture pour mon projet ?
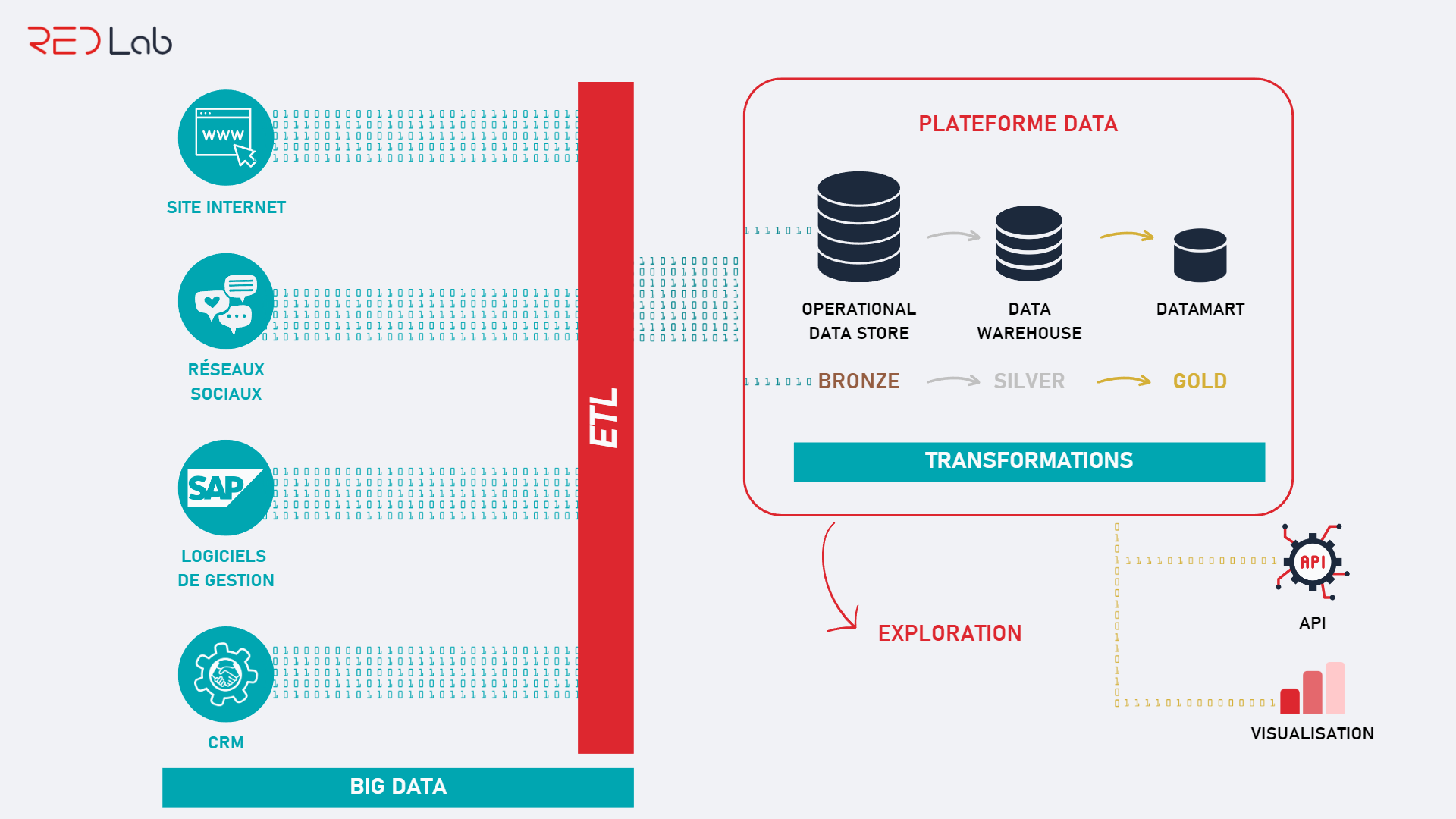
Exemple d’architecture data pour un cas d’usage d’analyse de la donnée
L’architecture à réaliser peut varier selon le projet.
Des fournisseurs externes proposent également des outils d’architecture qui intègrent toutes les technologies nécessaires au projet : Azure, AWS, Google, OVH Cloud, … Chaque fournisseur de Cloud développe et propose ses propres technologies, propriétaires ou non.
Il est également possible de mettre en place une architecture data on-premise pour répondre à certaines problématiques ou exigences : stockage de données confidentielles, sécurité, localisation des données…
REDLab est un pure player data, spécialisé dans les projets de traitement et de valorisation de données pour les grands comptes, start-up, et éditeurs logiciels.
Vous avez un projet data et vous souhaiteriez en discuter avec nos experts ? Venez découvrir notre façon de travailler et ce que nous pouvons faire pour vous :

Par Sarah
Sarah est Chef de Projet Data chez REDLab.
Rédaction Andréa Meyer





